




2 Proposals for improving Package Management Metadata
This section is taken from [EDO05].
After extensively studying various packaging systems (see Section 1), and in particular the mainstream ones based on either the DEB format or the RPM format, one is led to the conclusion that these systems are used to manipulate and maintain the relationships among a wide range of informations that span conceptually very different levels of abstraction, as well as different periods in the lifetime of the resources contained in a package (i.e., compile-time, run-time, configuration and installation)
In this section we describe three different proposals for improving package management systems by refining and reorganizing the metadata used to describe software packages, with respect to the aspects we are concerned in this part of the EDOS project, i.e., dependency management.
The proposals embrace three different perspectives:
- Adding some features to the existing metadata in order to improve the expressivity of the language used to describe dependency relations.
- Adding metadata information to better specify, maintain and manipulate the relationships among conceptually different levels of abstraction which currently are treated and encoded in the same syntactic way.
- Separating and rationalizing these information in order to improve its management and to guarantee a backward compatibility with the existing tools.
The following sections detail these three proposals.
2.1 Increasing the expressive power of the dependency description language
We claim that the constraint language used in the package formats we examined is not expressive enough: we will substantiate this claim with a real-world example, and propose an elegant solution.
2.1.1 Expressivity shortcomings: building the OCaml packages
One real example of the shortcomings of the current dependency constraint language is provided by the whole family of binary packages built out of OCaml sources using the bytecode compiler.
The OCaml language is a type-safe language which can be compiled either into native code or into portable, architecture independent bytecode. All packages containing OCaml bytecode need the OCaml bytecode interpreter specific to the target architecture to be run, and it is then natural for them to contain a dependency towards a package like ocaml-compiler-libs. This is not very different from the the situation of many scripting languages, up to this point.
The difference appears when one discovers that, because of the design philosophy of the language, an OCaml program, like Hevea, compiled into bytecode using the compiler in some version n needs the runtime system of exactly the same version n to be executed.
Now, this kind of constraint is currently not expressible, and what the maintainer does is to manually hardwire the dependency on a particular version of the compiler into the source package, by writing something like the following statements in the control file (the names of the OCaml packages deviate from the ones used in the real Debian distribution for the sake of clarity):
Package: heveaBuild-Depends: ocaml-compiler == 3.08, ...
Depends: ocaml-runtime-system == 3.08, ...
Now suppose the version of the OCaml compiler is stepped up to 3.09; the maintainer is forced to update the control file for hevea (and all the other OCaml bytecode packages) as follows
Package: heveaBuild-Depends: ocaml-compiler == 3.09, ...
Depends: ocaml-runtime-system == 3.09, ...
This has two major disadvantages:
- we need to modify the source package, despite the fact that the source itself did not change at all
- the source package is now hardwired to a specific version of the compiler, so that somebody having another version of the OCaml compiler (because she still lives in the Debian stable distribution, for example), will be unable to recompile the package.
2.1.2 A proposal: allowing binary constraints in dependencies
It seems clear that the right approach would be to allow binary constraints (remember that they are not expressible via unary constraints!) in the language, so that one can write in the control file once and forall the connection that must exist between ocaml-compiler and ocaml-runtime-system: this means we can express binary relationships between package names and variables (like N in the following example) instead of just relationschips with constants as in the current systems.
Package: hevea Build-Depends: ocaml-compiler == N, ... Depends: ocaml-runtime-system == N, ...
(Note: This section was written in 2005. Currently, in the year 2008, the system is somewhat more automatic in that the version of the ocaml compiler used for package compilation is filled in automatically.)
One could also allow adding some extra unary constraint to the connection variables like N via a Where: tag as in
Package: hevea Build-Depends: ocaml-compiler == N, ... Depends: ocaml-runtime-system == N, ... Where: N >= 3.0
which says that, whatever the version of OCaml we use, it must not only be the same for compiler and runtime, but must also be greater or equal to version 3.0.
This kind of constraints can be used in two ways:
- If the user just wants to compile the package using the OCaml compiler already available on her system, the constraint will ensure that the right version of the runtimes is fetched and installed.
- If the user wants to build a package for a given version of the runtime, the constraint will ensure that the right version of the compiler is fetched, installed and used.
Note that these variables are real logical variables, in contrast to the “variables” currently existing in the control file of a Debian source package (see Section 1.1.3). The currently existing “variables” are mere placeholders for values to be filled in at package compilation time, and are not used to express constraints on package relations.
These variables could also be used to express more complex relations. For instance, a package like Hevea might depend on an additional package providing some library only for certain versions of the runtime system:
Package: hevea ... Depends: ocaml-runtime-system == N, lib-ocaml-foo if N >= 3.5
As a side remark, notice that this extra power does not change the complexity class (the installation problem will still be NP-complete), but may be more costly in practice because more complex algorithms are needed to find a solution (we will need arc-consistency checks instead of node consistency).
2.2 Keeping semantically different metadata information separated
The current specification of both DEB and RPM package description format provides a very generic mechanism for describing package related metadata which enrich the standard inter-package relationships. This mechanism consists of the provides tag, which is present in both the DEB and RPM package description format, and which provides a totally generic and unstructured way of specifying additional package information that can be used when declaring package relationships.
As described in the previous section, the most natural way of using the provides tag is that of package group specification. By tagging a package using a provides clause, it is possible to logically associate that package to an identifier which will be then used by the package management system when trying to solve package dependencies. Of course, different packages can be associated to the same identifier, forming a group.
Even if this is a very powerful mechanism that adds a lot of flexibility to package metadata specification, it is very generic and unstructured and it is prone to tricky and undisciplined usages.
The trend in both RPM and DEB packages is to use (and abuse) the provides mechanisms in order to specify a wide range of useful metadata information regarding several unrelated semantical aspects.
In particular we have encountered that, above all in RPM packages, the provides tag is used to:
- Describe actual abstract (so called) capabilities provided by the package (e.g. MTA (Mail Transport Agent), smptd, smtpdaemon) that actually define package classes or groups.
- Describe some kinds of exported file-related information encoded as capability (e.g., /bin/bash)
- Describe some kind of capabilities not related to packages themselves but to the package management system (e.g., rpmlib(VersionedDependencies))
- Describe some kind of structured information even if the capability information is flat (i.e., it is treated as a plain string not as a string representing a structured information). For example perl(File::Find), /bin/bash, libc.so.6(GLIBC_2.0)
In particular what is written in the provide clause is often used to specify an arbitrarily encoded strings that further describe, in some way, the characteristics of a package.
For example, in the apache-ssl-jserv RPM package, there is the provided identifier webserver that tags the package as being part of the group of packages which exports the functionalities of a web server. The same package has even the apache-ssl -jserv identifier, that somehow, explicit that the package provides an Apache web server bundled with some additional functionalities (i.e. the ssl and jserv modules).
Often, the same type of information that could be reasonably included in metadata specification is encoded also in the package name. This is the case of many server or modular applications which can provide different kinds of functionalities, depending on how they are packaged or compiled:
- From a single source package we build several binary packages (this is normally done, for example, by differentiating the devel version of a package containing a runtime library) by varying the build options (e.g., incorporating some modular options directly in the package itself, kernel-2.4.9-3SGI_XFS_1.0.1.ia64.rpm, kernel-2.4. 22-1.2199.nptl.i586.rpm)
- Taking advantage of modular nature of the software we can combine and build a single package starting from different source distributions (e.g. apache and jserv), each one having its own independent evolution.
For example, we can find the following packages that are, basically, three flavors of the same web server application: apache-ssl-jserv-1.3.2,apache-ssl-1.3.6, apache-1.3.7.
The first one is a version of the Apache web server compiled with the mod_jserv and the mod_ssl extensions, the second one is a version of the same web server packaged only with the mod_ssl extension, and finally the third one is the plain version of the same web server again.
Encoding package information regarding something that can be still considered a capability in the package name is a widely used practice both in the RPM and in the DEB packages.
This fact poses the same dependency problems as for normal capabilities but at another level. This is true because what is encoded as an extension in the file name (e.g., mod_ssl) could be a versioned entity. In fact, many software are built in a modular and component oriented way, and the modules are often produced by someone else with their own versions, features etc. So we need to be able to specify metadata information even for modules and components bundled with a packaged software, in order to correctly reason on it.
A query on the package mentioned in the previous example executed on http://rpm.pbone.net reveals, in fact, that the mod_ssl bundled with the Apache web server is at version 2.0.12-1.3.2, and the mod_jserv is at version 0.9.11. Unfortunately this information is present in an unstructured format in the comment of the package itself and, from the point of view of an automated package management system, this information turns out to be completely useless
To partially solve this problem, one may decide that a module for an application should be packaged as a standalone package that can be installed on its own, but installing a module for an application often requires a modification of the configuration files of the same application, which is a dangerous and error-prone process.
While this problem is currently addressed and solved by making backups of the existing files, the approach taken by current package management systems does not take into account that there could be modules that, in some situations, simply could not be installed.
For example, if a server application is configured in a given way, an external module or an application which relies on a particular configuration of the server might not be installable. Since the information about the configuration of the application provided by a package is not exported explicitly by relevant metadata, what usually happens is that the package is nevertheless installed with the consequence of breaking the (good) configuration of the previously (working) applications.
At this point, it is clear that having a way for specifying in a generic way the metadata information gives a lot of flexibility for managing many of the previously described problems, but having a way for structuring such metadata information could be useful for increasing both the expressive power of the metadata provided with a given package and the reliability and effectiveness of actual package management systems.
This is the goal of the following sections where we describe with more detail the proposal to solve this kind of problems.
2.2.1 Additional metadata information
We have identified three main areas where it could be useful to have explicit metadata specification:
-
Definition of packages classes and grouping by capabilities. This is the current
standard usage of the provides tag for defining package classes, but
the need to make this grouping more structured, using something similar to an ontology,
is already apparent in the usage of the nonstandard field Tag: in some
Debian packages like the recent versions of binutils
Package: binutils Priority: standard Section: devel Installed-Size: 6004 Maintainer: James Troup <james@nocrew.org> Architecture: i386 Version: 2.16.1-2 Provides: elf-binutils Depends: libc6 (>= 2.3.2.ds1-21) Suggests: binutils-doc (= 2.16.1-2) Conflicts: gas, elf-binutils, modutils (<< 2.4.19-1) Filename: pool/main/b/binutils/ \ binutils_2.16.1-2_i386.deb Size: 2377880 MD5sum: 37a46d934443c096e217aec8b2a2e303 Description: The GNU assembler, linker and binary utilities The programs in this package are used to assemble, link and manipulate binary and object files.
They may be used in conjunction with a compiler and various libraries to build programs. Build-Essential: yes Tag: devel::machinecode, interface::commandline, \ role::sw:shlib - Package compilation options. This is a way of separating the information concerning what options have been built into the packaged software, giving them a clear semantic meaning. The information, that is currently present in an unstructured form both in the declared package provides and, often, even in the package file name, would be explicitly declared with a suitable expressive power, and made available for automatic processing of package management tasks. For example it would be possible to specify even the version of the built in modules (eg. apache version 1.3.2 with the module jserv version 0.9.11).
- Package configuration options. By specifying such a metadata
information it is possible to describe what are the configuration options
that have been used to configure the packaged software. These configuration
options might concern some of the dynamic attributes that characterize
a given package. For example, with respect to the web server Apache, a
configuration option will be the standard port where the server will listen
to, or the default set of modules that will be activated when the server will
start.
Since what is written in a package metadata is a merely static information, this class of metadata description might seem useless. In fact, after installing a package, for example a web server, configured to be run on the port 80, a system administrator could change that configuration parameter after the package installation. This would lead to an inconsistent information stored in the installed package database.
This problem could have different solutions:
- Actually ignoring the problem and treating, in case, the conflicts with respect to newly installed packages as warnings instead of errors. For example, if there is an installed web server configured to listen on the port 80, if we try to install another package that needs port 80 we might simply issue a warning. It will be the responsibility of the system administrator to check that the web server is currently configured to run on the port 80 before actually installing the package.
- Instrumenting the packaged software with additional utilities which give the system administrator a way to change every configuration option declared in the package and, indirectly, updates the relative configuration options associated to the package stored in the installed package database. This will maintain the consistency between the current package configuration and what is recorded in the installed package database.
Notice that configuration and compilation options really need to be distinguished and may not be grouped in the same semantic class: while compilation options are hard-coded in the software and cannot be modified once the binary package has been built, configuration options describe some aspect of the software that can be changed at installation time, or even later. Their specification (see Section 2.2.3) have the same characteristics, but they are treated in different ways: configuration options may simply raise warnings when some dependency relations are not satisfied; compilation options, instead, produce fatal errors when they do not satisfy some of the dependency constraints.
2.2.2 Namespaces
In order to suitably exploit the additional metadata information that we outlined above, it is necessary to structure that information in an hierarchical way. Indeed, many configuration or compilation options could be present, with the same meaning, in different packages. This is the case, for example, of the ssl support that can be configured/enabled in several network-oriented software.
By introducing the concept of namespace it is possible to distinguish and associate a given option to a well defined context. For example it would be possible to declare apache(ssl) and subversion(ssl) and give a structured way to the other package to refer to these options.
The syntax for declaring a namespace is the following:
This declaration will bind all the metadata to a particular namespace whose name is given by the identifier namespaceId.
An implicit namespace is defined by the package name. So any metadata information regarding a particular package is implicitly defined in the namespace of that package.
2.2.3 Options specification
Configuration and compilation options have one of the follwing different types:
- Boolean: the option indicates a functionality that can be enabled or disabled.
- Integer: the option indicates a parameter that can be set to a specific integer value.
- Generic: the option indicates a declarative parameter that can be set to a generic (string) value.
- Version: the option indicates a versioned entity such as a module or a component that has been configured to be used with the given software.
The syntax for declaring those options is the following:
where type is optional and can be one of the following: bool, int or ver. If the type information is missing, the option is treated as having a generic (string) type. If both type and value are missing then the declaration is a short version for a boolean option id:bool:true
Namespaces can be used in order to declare options for built-in or configured modules or components. Some examples of option declarations are:
- A boolean option
- ssl (or ssl:bool:=true)
- An integer option
- port:int:=80
- A generic option
- renderer:=opengl
- An option bound to a namespace
- modssl(version:ver:=0.9, md5, rsa, dsa)
2.2.4 Option relations
Once options have been declared, it should be possible to establish relationships among them in the same way it is possible to establish relationships between packages and their versions.
Essentially the types of relations of relations that can be established among options are the same ones used with respect to package versions: depends and conflicts. The first one denotes the option relations that must be satisfied, in order to correctly install the package; while the second one denotes the option relations that must not be satisfied in order to correctly install the package.
The operators we can use are the usual = and !=, which denote equality and inequality of option values (e.g., ssl = false, port != 80) and the other comparison operators <, <=, > and >=.
Obviously, since options are declared using a richer type system, the semantics of the previously described operators is dependent on the type of the options.
Moreover, since the difference between compilation and configuration options is just a matter of being immutable or not, when specifying option relations we do not differentiate between the two. It will be the package management system that when an option constraint isn’t met will issue a warning in case of a configuration option or an error in case of a compilation option.
In order to specify option relations we use the following tags:
Namespace bound relations can be specified using the following syntax:
In this case, all the relations will be verified against the options declared in that namespace. For example Option-depends: apache(modssl(version=0.9, md5)) specify that the current package needs an option (module) modssl declared in the apache namespace. The version and md5 options are bound to the modssl namespace. This example, finally, states that the current package needs an apache webserver configured with a modssl module whose version is 0.9 and it has been compiled with the support of the md5 algorithm.
In the previous example md5 is a shorthand for md5:=true. When a boolean option is mentioned in a relation but is not declared in neither Configuration-options nor in the Compilation-options it is assumed to be bound to the false value.
Finally, the following list shows how options could be declared in the context of a package metadata specification.
- Specification for a plain Apache web server
-
Package: apache Version: 1.3.7 Configuration-options: port:int:=80 - Specification for an Apache webserver compiled with modssl
-
Package: apache-ssl Version: 1.3.7 Configuration-options: port:int:=80 Compilation-options: modssl(version:version:=0.8, sha, md5) - Specification for an independent Apache modssl module
-
Package: modssl Version: 0.9 Compilation-options: sha, md5 Option-conflicts: apache(modssl)
In particular the second case in the above list shows the options by using a namespace modssl for defining the way the optional module modssl has been configured, compiled and packaged with the Apache web server. The last case, in contrast, shows an independent modssl package that specify an Options-conflict with the modssl option defined in the apache namespace.
When specifying a Options-depends or Options-conflict relation we can refer to several options defined in a namespace. All the option relations specified must be satisfied by some configuration or compilation option declared in some package. If a package declares a superset of the options specified in the dependency relation, all the options that do not appear in the dependency relations are treated as don’t care.
When we specify a generic option (a string) in a dependency relation it may refer either to a boolean option that must be set to true or to a given namespace that must have been declared. For example the Options-depends: apache(modssl) relation would be satisfied both by a package which declares a modssl option in the apache namespace, or by a package which declared no matter what options in a apache(modssl(...)) namespace.
2.3 Separating metadata information
Most of the metadata information that is currently hard-coded in the package itself could be specified outside the package itself. This is particularly true above all with respect to the definition of package classes through the standard provides tag. Currently the class the package belongs to is defined by the package maintainer and is his own responsibility to choose the class identifier by actually hard-coding it in a static way in the package provides information. This is not a very flexible way to do this because:
- Package classes might vary during time: a package might be added or removed to a package class for various reasons .
- Different systems might have different package class definitions:
what is a web server class for a distribution vendor might not be
the same thing for another vendor and, moreover, the class identifier could
be also named differently.
Hard-coding a package class as a capability directly into the package metadata information would determine, once and for all, the class the package (with that version) belongs to.
Separating this kind of information would, then, have those benefits:
- It will make possible to vary at later time the specification of the metadata information without altering the package it refer to (and, therefore, its version).
- Redistribute the responsibility of defining package related information among many persons instead of only the packager, i.e., give, for example, the vendor the power to decide what package belongs to what class for its own software distribution.
- As a consequence of the previous point, by separating and redistributing the roles in the package creation and maintenance process, the whole management is streamlined and made more efficient.
In order to do so, however, there should be an infrastructure where it is possible to store the metadata and the mappings towards actual packages. Such an infrastructure is shown in Figure 8. Package providers specify also metadata information and export it towards package management system by means of servers. Package providers may be either usual software distribution vendors (e.g., Mandriva, RedHat, etc.), or independent (and trusted) organizations which can provide themselves classifications for existing packages.
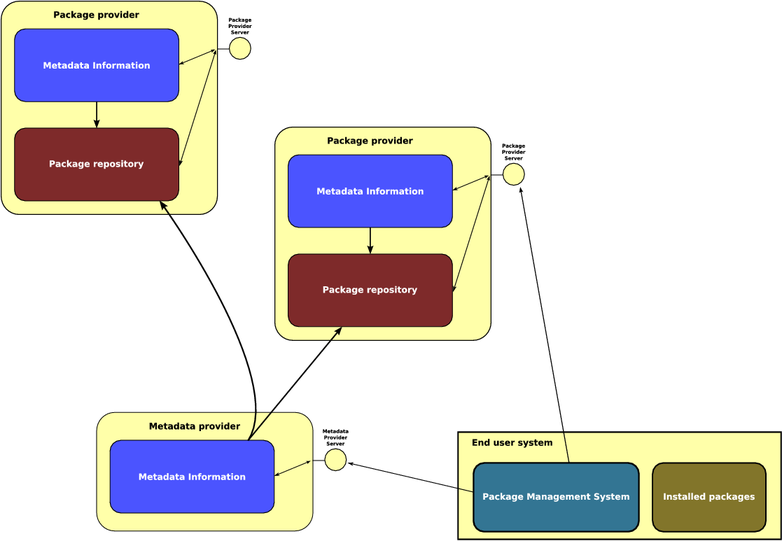
Figure 8: Metadata server infrastructure
2.3.1 Backward compatibility
This infrastructure does not require any modification to the current packages and their format. The information provided by the infrastructure can be used to complement or override the information that is hard-coded into package information metadata if the user requires so, but can be completely ignored otherwise.
2.3.2 Impact on the existing tools
The impact on existing tools is also minimal. During the package database information parsing phase, an existing tool could add to its internal representation the additional information coming from the external metadata servers specified by the users, after pre-processing the options into the internal representation of specially named provides tags. Once that is done, the usual algorithms for discovering a solution of the constraint could be used without modifications.
2.4 Remarks and related work
The previously described proposals entail several consequences. First of all, describing new metadata information poses an ontology design problem. On the other hand, building an infrastructure for supporting the new features of the package management and distribution system introduce the classic architectural problems that we have when we build complex and distributed systems.
Of course these problems are out of the scope of this deliverable and even of the relevant topics addressed by Work Package 2. However it is interesting to point them out.
In particular, with respect to the ontology perspective, we cite the AMOS project [amo] which addresses the problem of “building an ontology of open source code assets and a tool which helps the programmer to select, among all the described packages, those which are more promising for developing the desired software”. This work is closely related to what we have described so far, even if it addresses a different (and more general) problem concerning software development and open source software categorization and search engines. However it could be interesting to investigate the adopted solutions in order to reuse them in our context.
On the distributed infrastructure side, instead, we must face the classic problems related to information distribution, synchronization and trust. Actually these topics are closely related to the ones addressed by the EDOS Project Work Package 4. This fact strengthen the relationships and the synergy between the different perspectives addressed by the EDOS Project.
Finally, it is worth to mention the W3C Member Submission regarding Installable Unit Package Format Specification [WCIa]. This document describes an XML specification for describing installable packaged software units. Even if this initiative seems to completely overlap the problems we addressed, actually it simply proposes a meta format in order “describe a common installable unit package format [...] that is compatible with existing standard or de facto standard formats [...] and that encapsulates and uses the existing install technologies for the various hosting environments”. In practice it doesn’t address directly the problems we have with the description of fine grained features (such as package dependencies) but it only propose a generic and extensible way to describe high level package characteristics, leaving the responsibility of handling the actual problems to currently available technologies. Nevertheless, the design solutions proposed in this work, can be useful for refining the specification of the metadata information distributed using the infrastructure described in Section 2.3.